OpenML
02 May 2016OpenML is a very cool new online platform that aims at improving - as the name says - Open Machine Learning. It stands for Open Data, Open Algorithms and Open Research. OpenML is still in it’s beta phase, but already pretty awesome.
With this blog post I would like to introduce the main concepts, show who should be interested in the platform and I will go a little into a challenge it faces.
Concepts
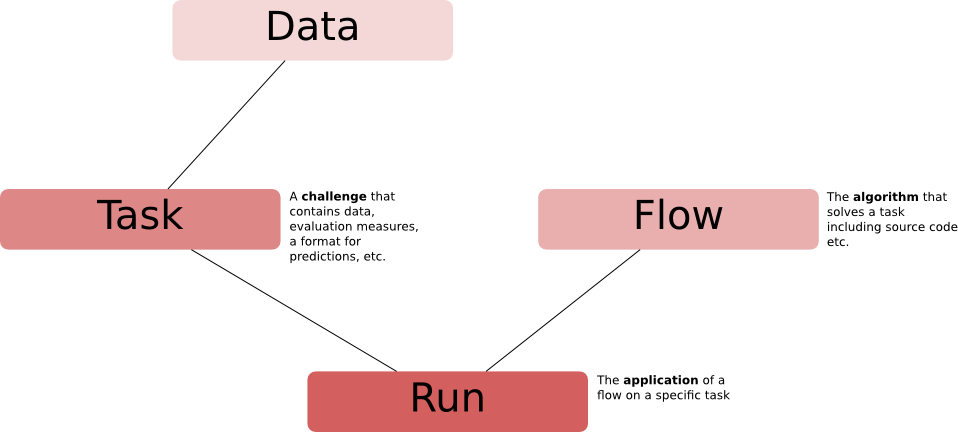
The following four concepts form the basis of the platform:
- data
- task
- flow
- run
The figure shows how they are connected.
Who can make use of OpenML?
The domain scientist
You have data that you do not know how to analyse best? Upload your data to OpenML and you will have the whole world helping you. Write a good data and task description to make sure people understand the problem.
The data analyst
You like taking part in challenges? Being the best solver of a task? Go to OpenML and check out the many tasks and go solve!
The algorithm developer
You developed a statistical method or a machine learning algorithm and want to try it out? You will find plenty of data sets and the possibility to make your algorithm public.
The student
You study statistics, data science, machine learning? You want to know what is out there? On OpenML you will find a wide variety of algorithms and, if the solvers do a good job, info on software and implementation.
The teacher
You teach a machine learning class and want the students to participate in a challenge? Make up your own task and let the students try solving it. The platform shows who uploaded what and when.
The unknown
There are possibly many other people who will benefit from the platform, like meta analysts, benchmarkers and people I can not think of right now.
How to use OpenML
Other than just browsing the website you can access OpenML through quite some interfaces such as R or WEKA. For an example on how to use the R interface check out the tutorial.
The whole project is of course open source. Check out the different git repositories for all the code and in case you have any complaints.
The overfitting problem
Platforms like kaggle, crowdanalytics and innocentive host challenges and give people only part of the data so they can evaluate the performance of the algorithm on a separate data set to (try to) prevent overfitting. So far OpenML does not do that. It always shows all the data, and algorithms are evaluated via resampling procedures (on OpenML called estimation procedures). There are big discussions about how to solve the problem of overfitting on OpenML. They go from keeping part of the data hidden for a certain time in the beginning to doing repeated cross-validation on the (overly) good performing flows on a given task. If you have ideas here, please don’t hesitate to leave me a comment.
The platform is still in it’s childhood and may not be perfect yet (If you find issues, post them on the github page). But I think it can grow to be a great thing one day.